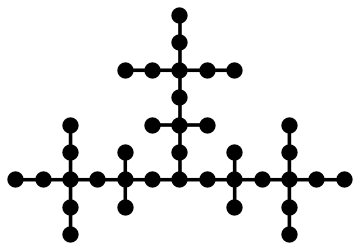
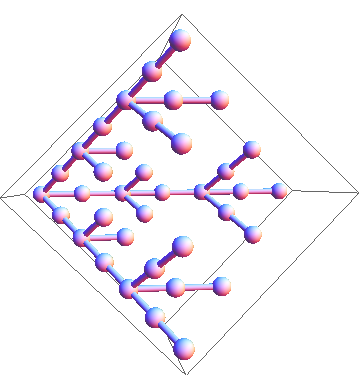
Weighted Mediants
Let us start with regular (non-weighted) mediants. Suppose we have two fractions a/b and c/d, the mediant of these two numbers is the wrong way a child might sum these two fractions: (a+c)/(b+d). There is nothing wrong with this childish way of summing, it is just not a sum of two numbers, but rather an operation the result of which is called a mediant. One must be careful: the result doesn’t depend on the initial numbers chosen, but on their representations. The way to deal with this is to assume that a/b, c/d, and (a+c)/(b+d) are in their lowest terms.
The numerical value of the mediant is always in between given numbers. This is probably why it is called a mediant.
Suppose you start with two rational numbers 0/1 and 1/1, and insert a mediant between them. If you continue doing it recursively, you can reach any rational number between 0 and 1. This is a well-known property of the mediants. For example, after three rounds of inserting mediants into the initial sequence (0/1, 1/1), we get the sequence: 0/1, 1/4, 1/3, 2/5, 1/2, 3/5, 2/3, 3/4, 1/1.
The mediants are easy to generalize if we assign weights to initial fractions. Suppose the first fraction has weight m and the second n, then their weighted mediant is (am+cn)/(bm+dn). The simplest generalization happens when the total weight, m+n is 3. In this case, given two rational numbers a/b and c/d, the left mediant is (2a+c)/(2b+d) and the right one is (a+2c)/(b+2d). Obviously the inequality property still holds. If a/b ≤ c/d, then a/b ≤ (2a+c)/(2b+d) ≤ (a+2c)/(b+2d) ≤ c/d.
James Propp suggested the following question for our PRIMES project. Suppose the starting numbers are 0/1 and 1/1. If we recursively insert two weighted mediants in order between two numbers we will get a lot of numbers. For example, after two rounds of inserting weighted mediants into the initial sequence (0/1, 1/1), we get the sequence: 0/1, 1/5, 2/7, 1/3, 4/9, 5/9, 2/3, 5/7, 4/5, 1/1. It is easy to see that new fractions must have an odd denominator. Thus unlike the standard case, not every fraction will appear. The question is: will every rational number between 0 and 1, which in reduced form has an odd denominator appear?
I started working on this project with Dhroova Aiylam when he was a high-school junior. We didn’t finish this project during the PRIMES program. But Dhroova finished another project I already wrote about: he analyzed the case of the standard mediants with any starting points. He showed that any rational number in between the starting points appears.
Dhroova became an undergraduate student at MIT and we decided to come back to the initial PRIMES project of weighted mediants. In our paper Stern-Brocot Trees from Weighted Mediants we prove that indeed every fraction with an odd denominator between 0 and 1 appears during the recursive procedure. We also analyzed what happens if we start with any two rational numbers.
Share: