Karabegov’s Conjecture. Any finite planar point configuration in which every point has exactly 3 closest neighbors must contain at least 16 points.
The conjecture was proposed by my dear friend Alexander Karabegov, whom I met in 1974. Wait. What?! I just realized that this was more than 50 years ago. How is that even possible?
After I posted the conjecture, we couldn’t resist working on it. We wandered through different types of graphs and found many cute definitions related to our problem.
A unit distance graph is formed from points in the plane by connecting two points whenever they are exactly distance 1 apart. A matchstick graph is a unit distance graph that can be drawn in the plane with edges of length 1 that do not cross. In other words, it is a unit distance graph that behaves nicely, by being planar. Think of laying matchsticks flat on a table: no overlaps, no chaos.
Here’s the difference visually: the left graph is a unit distance graph, while the right one is a matchstick graph.
Now for the star of the story. A penny graph connects two vertices if and only if their distance is the minimum distance among all pairs of vertices. The name is delightfully literal: imagine placing identical pennies at each vertex so that they do not overlap. Two pennies touch exactly when the corresponding vertices are connected by an edge. A penny graph is a special kind of matchstick graph: two vertices that are not connected are at a distance that is longer than the length of the matchstick.
Finally, a 3-regular graph is a graph where every vertex has degree 3. Three neighbors. No more, no less. They are also called cubic graphs. Not surprisingly, if the vertices of a cube are the vertices of our graph, and the edges of a cube are the edges of our graph, we get a 3-regular graph, as each vertex is incident to exactly 3 edges. Surprisingly, such graphs are not called tetrahedron graphs, as a tetrahedron, too, has each vertex incident to 3 edges. But the tetrahedron graph is special: it is a minimal 3-regular graph.
We wrote a paper Minimal 3-regular Penny Graph, in which we proved the conjecture. The conjecture has officially graduated to a theorem.
Theorem. The minimal 3-regular penny graph has 16 vertices.
I recently gave my STEP students a question from our old 2014 PRIMES entrance test.
Puzzle. John’s secret number is between 1 and 216 inclusive, and you can ask him yes-or-no questions, but he may lie in response to one of the questions. Explain how to determine his number in 21 questions.
Here is the standard solution. We start by asking John to convert his number into binary and add zeros at the beginning if needed to make the result a binary string of length 16. For the first 15 questions, we do the following. For question i, we ask: “Is the i-th digit of your string zero?” For question 16, we ask, “Have you lied in response to a previous question?” If he lied on a previous question, he must say YES. If he didn’t, he might lie on question 16 and also say YES. In any case, if the answer is NO, he didn’t lie on the first 15 questions and we know the first 15 digits of the number. Then, we ask about the last digit three times, and the answer given at least twice is correct, so we know the number.
If the answer to question 16 is YES, then he lied on one of the questions 1–16. From now on, he has to tell the truth since he already lied. We use binary search (4 questions) to determine on which question he lied. This will tell us the first 15 digits, and we can use the 21st question to find the last digit.
One of my students, Tanish, invented an out-of-the-box solution that uses 18 questions. The idea is to force John to lie in the first two questions, and then safely proceed with the binary search.
He suggested asking the following two questions: “Are you going to answer NO in response to the next question?” and “Did you respond YES to the previous question?” The reader can check that whatever John replies, he is forced to lie exactly once.
Another student, Vivek, had a similar idea but used only one question to force John to lie: “Will you say NO to this question?”
Imagine you’re watching a magician. She pulls out two perfectly ordinary boxes — or so it seems. One box is inside the other, like a set of nesting dolls. So far, nothing suspicious.
Then she removes the smaller box, closes the larger one, and slides the larger box inside the smaller one. Ta-da!
The name comes from the way one box goes into the other. Would you like to know the secret? The two boxes are actually identical. Moreover, they are not cubes but cuboids. The inner box is fully closed, while the outerbox is slightly expanded, and the inner box is rotated relative to the outer one.
I first heard about Gozinta Boxes at the Gathering for Gardner conference in 2024. Ivo David gave a talk and presented his new trick: Triple Gozinta Boxes, which you can now buy at TCC Magic. He can place three boxes inside one another — and then repeat the trick in the reverse order.
During his presentation, David mentioned that he knew how to prove that you cannot have more than ten Gozinta Boxes. My immediate reaction was that ten must be overkill. So I decided to give the problem to my STEP students as a project.
We proved that in three or higher dimensions, the maximum number of boxes is three. We also showed that in two dimensions, the maximum is four. You can find all the details in our paper Mathematics of Gozinta Boxes, posted on the arXiv. But we didn’t stop there. We invented a new trick. We constructed three boxes such that not only can they be nested in one order — say, ABC — and in the reverse order, CBA, but they can also be nested in three additional orders, for example ACB, BAC, and BCA. We also proved that achieving all six possible orders is impossible. You can see the trick by following the link for A New Gozinta Boxes Trick.
I met Alexander Karabegov during the All-Soviet Math Olympiad in Yerevan. He was one year older than me. By then, when I was still competing in 1976, he was already a freshman at Moscow State University. He proposed the following two related puzzles for the Moscow Olympiad, which I had to solve.
Puzzle 1. You are given a finite number of points on a plane. Prove that there exists a point with not more than 3 closest neighbors.
Just in case, by closest neighbors I mean all points at the minimal distance from a given point. I am sure I solved both puzzles at the time. I leave the solution to the first one to the reader.
Puzzle 2. Can you place a finite number of points on the plane in such a way that each point has exactly 3 closest neighbors?
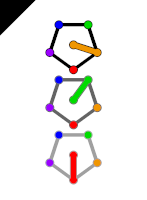
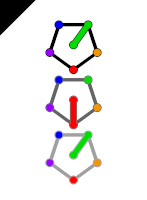
The last problem has an elegant solution with 24 points chosen from a triangular grid. The story continued almost 40 years later, when Alexander sent me an image (below) of such a configuration with 16 points. He conjectures that this is the minimal configuration.
Karabegov’s Conjecture. Any finite planar point configuration in which every point has exactly 3 closest neighbors must contain at least 16 points.
Can you prove it?
Initially, I didn’t want to give the 24-points solution, but the image above is a big hint, so here you go.
Both constructions reveal the same underlying pattern. The constructions consist of rhombuses formed by two equilateral triangles, and the rhombuses are connected to each other. The 24-point construction consists of 6 rhombuses, while the 16-point construction consists of 4 rhombuses. What will happen if we try the construction with 3 rhombuses? The image below shows such a configuration, which now has extra edges with the shortest distance. We now see 3 points with more than three closest neighbors each, violating the condition. So the conjecture doesn’t break.
So far, every smaller attempt failed — can you prove that 16 is minimal?
Once I wrote a blog essay titled Seven, Ace, Queen, Two, Eight, Three, Jack, Four, Nine, Five, King, Six, Ten. It was about a “magic” card trick. Magic trick. Take a deck of cards face down. Move the top card to the bottom, then deal the new top card face-up on the table. Repeat this process until all the cards are dealt. And — abracadabra — the cards come out in perfect order!
If you want to perform this trick with one suit, the title of that earlier post tells you exactly how to stack your deck.
In the fall of 2023, I gave this trick as a homework problem to my STEP students. The result? We ended up writing a 40-page paper, Card Dealing Math, now available on the arXiv. At one point, we seriously considered calling it The Art of the Deal, but decided against it.
In the homework version, the deck consisted of cards from a single suit, but we generalized it to a deck of N cards labeled 1 through N. The dealing process we studied is called under–down dealing: you alternate between placing one card under the deck and then dealing the next one face-up. It’s very similar to down–under dealing, where you start by dealing the first card instead. These two patterns are often, unsurprisingly, called the Australian dealings.
The under-down dealing turns out to be mathematically equivalent to the Josephus problem. In that famous ancient problem, people are arranged in a circle, and you repeatedly skip one person and execute the next (much grimmer than playing with cards). The classic question asks: given N people, who survives? In our card context, this corresponds to asking where the card labeled N ends up in the prepared deck.
More generally, the Josephus problem can ask the following question. If we number the people in a circle 1 through N, in what order are they eliminated? In our research, we flipped the question around: how should we number the people in the circle so that they’re eliminated in increasing order?
Naturally, we couldn’t stop there. We explored several other dealing patterns, discovered delightful mathematical properties, and along the way added 44 new sequences to the OEIS. The funnest part? We also invented a few brand-new card tricks.
We recently wrote a blog post on how to generalize the game of SET and promised to continue. Here we are. But first, a reminder of what the game of SET is.
In the game of SET, we have 81 cards, each containing one, two, or three of the same object. The object is green, red, or purple, the shape is squiggly, oval, or diamond, and the shading is empty, full, or stripped. Three cards form a set if, for every feature, the attributes are all the same or all different. An example of a set with all features different is shown below. By the way, such sets are usually more difficult to spot. In the game, you need to find sets as fast as you can.
If we assign each attribute value a number 0, 1, or 2, we get an equivalent definition of a set. Three cards form a set if and only if the values for each feature sum to zero modulo 3. Thus, we can see our cards as vectors in the space F34. Three vectors form a set if they sum up to 0.
The generalizations we described in the previous post, were the following. We pick a different group and define a set as a few cards that might need to be in a specific order that multiply to the group’s identity.
However, there is a different way to generalize sets to groups. Three cards that form a set in a classical game of SET, taken in any order, form an arithmetic progression. In other words, if a, b, and c form a set, then vectors b−a and c−b are the same. We can check this. We have c−b = c−(c+b+a)−b =−2b−a = b−a.
Thus, we can generalize the game of SET differently. Suppose cards are vectors in some space. We say three of them, a, b, and c, form a set if and only if b−a = c−b. Now, the order becomes important, similar to our previous generalization. We do not need to use commutative groups like vector spaces. For any group, our condition is equivalent to ba-1 = cb-1. Thus, c = ba-1b.
Interestingly, we do not care much about the identity card, meaning the card deck is a torsor. We introduced the notion of a torsor before, which informally is a group that forgets about its identity. Now, let’s check possible examples.
Suppose the values of one attribute correspond to Z4. This game is not very inspiring as two values, a=0 and b=2, can be completed to a set with the third card, which equals c=(0,0,0) and is already used. The next interesting example is Z5. Here, values a=0 and b=2 can be completed to a third value c=4. We will leave it to the reader to check that for any two cards, a and b, the third card, c, differs from both a and b.
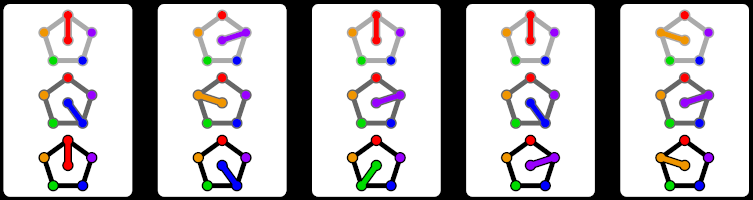
To make it more visual, we can use a pentagon with one marked direction. We fix the pentagon in space. In this case, three cards form a set if and only if the directions of the first and the third card are symmetric with respect to the direction of the second card. If we want to use three pentagons, we can reuse the cards from the game C53T, we described in our previous post. To make this game more visual, we can use three pentagons. We can mark each coordinate with a direction on the corresponding pentagon. The colors are to allow players to visually process the cards faster. For theoretical purposes, the colors can be ignored. Also, the pentagons themselves have different intensities of gray to emphasize that the game is played on each of them separately and also help choose the top of the card.
Let us go back and calculate when it is possible that the element that completes a set is already used. If our initial elements are a and b, then we need ba-1b to complete a set. If this element is equal to b, then a = b, which contradicts the assumption that we start with two different cards. Suppose ba-1b = a, then, equivalently (ba-1)2 = 1. The new element can be the one that is already used if and only if the group contains elements of order 2.
Can we use other decks we described in the previous post? Consider the game ProSet/Socks. The group is commutative, and every element is of order 2, which means ba-1b is always a. We can’t use the deck at all! What about the EvenQuads deck? It can be viewed as Z43, so it is possible that we can’t complete any two cards to a set. However, there is a bigger problem with the deck. To play with it, we need to actually assign values to colors and shapes. We are saying that even if we decide to use the group, we should make different cards! For example, we can style the cards as squares like the pentagons above.
We also mentioned in the previous post the group, which is the wreath product of S2 and S3. Consider the following example of two cards that were screen-printed from the Numberphile video on the variations of the game of SET.
The first card, a, is the inverse of itself, so the third card we are looking for is described as the product bab, which we can visualize as the following. If we ignore the beads, the card that completes the set is a. Luckily, if we do not ignore the beads, it is not a; we need to add two beads to a.
The product of permutations is difficult to visualize, so playing this game with the cards in the Numberphile video might be difficult. The good news is that this group can be visualized in many different ways:
The group of symmetries of a cube, meaning its rotations and reflections;
The group of symmetries of an octahedron, meaning its rotations and reflection;
The wreath product of S2 and S3;
The direct product of S4 and S2.
We want to show you a beautiful deck from the tsetse website that allows you to use any one of the four definitions to play the game. The game is called OCTA Set, as the underlying group is called an octahedral group. An example of a set is in the image below, where the top and bottom shapes represent the same element of the group. Moreover, the deck is a torsor: there is no the identity card.
The top shape represents an octahedron where the opposite faces are the same color. Thus, the top shape shows a unique rotation of an octahedron. All the swirls are the same in the image, but in other cards, the swirl could be white. Two different swirls mean that the octahedron needs to be reflected to get from one shape to the other. In our example above, no reflection is involved, so all the swirls are black.
We can ignore that the top shape represents an octahedron and only look at the choice of colors. The changes of colors represent a permutation in S4 and a swirl represents an element in S2.
The bottom shape represents a cube where the opposite faces are the same color. One of the faces is solid, and the opposite face is hollow. This way, one can reconstruct the complete shape of a cube by the top three faces.
We can ignore that the top shape represents a cube and only look at the choice of colors. The colors form a permutation, and the beads correspond to changing the hollowness of a color. When viewing the cube this way, the permutation acting on the colors is S3, and each color has its hollowness associated with an element of S2. This exactly corresponds to the wreath product of S3 and S2.
Let us prove that this is a set. Consider the bottom cube shape. Comparing the first two cards, the top face doesn’t change. We can see that the symmetry of the cube is the 90-degree clockwise rotation around the line that goes through the centers of green faces. In such a rotation, the left face on the second card keeps the color from the first card, while the right face takes the color from the left face on the first card and swaps hollowness. We see that the third cube completes the set.
For another proof, let us look at the top shape and discuss what happens with the permutation of colors when changing from the first card to the second. The left color moves to the bottom, the bottom color to the right, the right color to the center, and the center color to the left. Not surprisingly, we got a cyclic permutation of order 4, similar to a 90-degree rotation being of order 4. The same thing happens when moving from the left to the right. The swirl stays the same.
As we mentioned, when you play this game and pick two cards then calculate what card completes the set, you might discover that it is one of the cards you picked. The probability that two cards in a specific order can’t be completed into a set is the same as the probability of picking a random element in our group and discovering that it has order 2. The symmetric group S4 has 9 elements of order 2. Thus, the direct product with S2 has 19 elements of order 2, giving a probability of 19/48. For completeness, this group also has 8 elements of order 3, 12 elements of order 4, 8 elements of order 6, not to mention the identity of order 1.
If ba-1 is an element of order three, then the cards a, b, and the card c that completes the set form a set when they are taken in any order. As a tradition in mathematical writing, we leave it to the reader to check that fact. Just a reminder that in the game of SET, the group element ba-1 always has order 3.
Notably, there was nothing special or extraordinary about the group discussed above. It has a pretty visualization as a cube or octahedron, but is not otherwise particularly interesting. The reason why this group allowed for these two platonic solids to be used to visualize it is because the cube is dual to the octahedron. But we could have similarly used any group to play set! One such example might consider using the group of symmetries of the other pair of dual platonic solids, the icosahedron and the dodecahedron. This group is actually equivalent to A5, also known as the alternating group of order 5, which consists of all even permutations of five elements. The tsetse website we mentioned above contains an implementation of such a game called A5SET (pronounced “asset”). The design of the site, games, and cards was done by Andrew Tockman and Della Hendrickson.
The world is full of groups and symmetries. Any group can be turned into a game of SET!
Foams are cool mathematical objects studied by my brother, Mikhail Khovanov. I already wrote about them in my previous blog posts, Foams Made out of Felt and Tesseracts and Foams. Here, I would like to explain why foams are so cool, but first, I need to remind you of their definition. Foams are finite 2-dimensional CW-complexes, such that each point’s neighborhood must be homeomorphic to one of the three objects below.
An open disc. Such points are called regular points.
The product of a tripod and an open interval. Such points are called seam points.
The cone over the 1-skeleton of a tetrahedron. Such points are called singular vertices.
Foams are cool: they are 2-dimensional CW-complexes embedded in 3-space, with singularities only of the most generic kind, which makes them relatively simple. Moreover, they are combinatorially defined, which makes them easier to work with than with many other geometric objects.
My two previous blog posts have some pictures, but now, I just want to discuss a generic planar cross-section of a foam, which is a planar graph. In the cross-section, seams become vertices, and faces (regular points) become edges. The tripod condition above implies that the resulting graph is trivalent: each vertex has degree 3.
The most interesting foams are tricolarble: foams where their faces can be colored in three colors, so that each face has its own color, and, at the seams, three faces of three different colors meet. The cross-section of such a foam makes a tricolorable trivalent graph. This coloring is called Tait coloring. The cool thing is the Tait’s theorem connects the Tait coloring to the 4-color theorem.
Tait’s theorem. The following two statements are equivalent.
Every planar graph is 4-colorable.
The edges of every planar bridgeless trivalent graph are 3-colorable.
I won’t discuss the proof here, but I will explain how to color the edges of a graph in three colors when the faces are colored in four, and vice versa.
Assume that the four colors of the faces form a group of four elements, called the Klein group. Let’s say that gray is the identity, and red, blue, and green are the rest. Then, the product of gray and x is x. The product of any two non-gray colors is the third non-gray color.
Given a trivalent graph G whose edges are colored in three colors, we can color the faces of that graph in the following manner. Color one of the faces a random color. Then, calculate the colors of the other faces so that each edge’s color is the product of the colors of neighboring faces.
Going back, if we have a planar trivalent graph with faces colored in four colors, we can assign an edge a color that is the product of the colors of neighboring faces. As neighboring faces have different colors, the product of those colors is never gray (the identity). Thus, the edges will be colored in three colors. I leave it to the reader to check that three edges incident to a vertex must be colored in different colors.
Kronheimer-Mrowka homology theory of graphs states that the Kronheimer-Mrowka homology of a trivalent graph is non-zero if and only if the graph has no bridge. If one can prove that the rank of the homology group is the number of 3-colorings of the edges (or at least that the non-zero homology implies the existence of the tricoloring of that graph), then the Four-color theorem would follow from Tait’s theorem.
Foams are cool by themselves, but there is hope that they might provide a conceptual proof of the Four-color theorem, making them awesome!
Do you know that 2025 is a composite, deficient, evil, odd, square, and powerful number? I collect properties of numbers at my Number Gossip website, where you can also find detailed definitions of these terms. Provocatively, 2025 is also an apocalyptic power, meaning that 2 to the power of 2025 contains 666 as a substring.
Recently, Tamas Fleischer sent me an email discussing additional fascinating properties of 2025. While I am slowly deciding whether to add them to my database, there is some urgency in posting these properties in anticipation of the coming year. Here’s the material from Tamas, retold in my own words.
Out of the properties mentioned earlier, the square property is the only rare one. On my website, I define a property as rare if fewer than 100 numbers below 10,000 possess it. Square numbers barely make the cut. But 2025 is not just a square number—it is the square of a triangular number. If you remember the formula for the sum of cubes of the first n natural numbers, the result is (n(n+1)/2)2, which is the square of the nth triangular number. Thus, 2025 is the sum of the cubes of all one-digit numbers.
Additionally, 2025 is the product of 25 and 81. My website notes an intriguing property shared by 25 and 2025: both remain square numbers when all their digits are incremented by 1. For example, 25 becomes 36, and 2025 becomes 3136, both of which are squares. Moreover, 25 is the smallest such number, and 2025 is the second smallest. What my website does not mention is that their square roots exhibit a similar pattern. The square roots of 25 and 2025 are 5 and 45, respectively. When their digits are incremented by 1, the results are 6 and 56, the square roots of 36 and 3136, respectively. The original and incremented squares and their square roots are tied together in a surprising way.
2025 also shares an interesting property with 81. Both are square numbers with an even number of digits and if you split the digits in half and sum the halves, the result is the square root of the original number. For 81, splitting into 8 and 1 gives 8 + 1 = 9, which is the square root of 81. Similarly, for 2025, splitting into 20 and 25 gives 20 + 25 = 45, the square root of 2025. Intriguingly, 81 is the smallest number with this property, and 2025 is the second smallest.
The deck for the game of SET consists of 81 cards. Each card has 1, 2, or 3 identical objects. Each object is an oval, a diamond, or a squiggly, colored in red, green, or purple, and the shading can be solid, striped, or empty. Three cards form a set if, for each feature (number, shape, color, shading), all three are either the same or all different. For example, one red striped squiggly, two red striped ovals, and three red striped diamonds form a set. The numbers are all different (1, 2, and 3); the shapes are all different (squiggly, oval, diamond); the color is the same (red), and the shading is the same (stripped). Another example of a set with all features different is shown in the picture.
For every feature, we can assign values of 0, 1, 2, modulo 3. The fact that the values are the same or all different is equivalent to saying that the values sum up to zero modulo 3. Thus, we can view the cards as points in a 4D vector space over the field F3, namely F34. Three cards form a set if and only if the corresponding vectors sum up to the zero vector. Sets have a very useful property: for any two cards in a deck, there exists a third card that completes the given two cards to a set.
Before we generalize the game of SET, let’s talk about notation. Above, we looked at the values we assign for one feature as the field F3. If we want to talk about vectors, since technically a vector space must be over a field, we could use this definition. However we do not use its multiplicative properties, so we can say that values for one attribute are in Z3. If we want to forget about the exact values, and just use the group structure, we can use notation C3.
Let’s see in what ways we can extend this definition. People have tried to generalize the game of SET to a group. Suppose each card corresponds to an element in a group. Then, we want to arrange three cards so that the corresponding three elements multiply to the identity. If the group is non-commutative, then the order matters. That means the players do not just pick out the three cards, they have to arrange them in a line so that the corresponding product is the identity. However, we still retain a useful property. If our card deck contains all possible elements of the group, then for any two cards in a given order, there exists a card that completes them to a set so that the product is the identity. However, another problem is that this card might be one of the cards we already have. On the plus side, we can rearrange the order of the cards, getting more options. We can also say that a set can consist of any number of cards, not just 3, as long as the product is the identity.
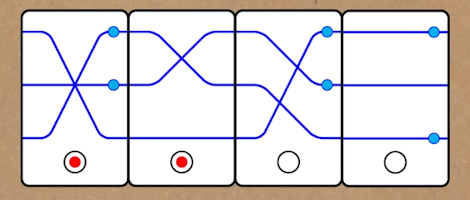
The Numberphile video The Game of Set (and some variations) shows examples of such games. One of the decks they show represents the group S3: permutations of 3 elements. The picture shows a screenshot from the video with a set in a different group, but if you ignore the blue beads, you will get a set in S3. The red dots at the bottom mark odd permutations. This helps see sets faster: each set has to have an even number of red dots. This deck is a toy example of what is possible with only 6 elements in the group.
They also show a similar deck corresponding to group S4: permutations of 4 elements. Thus, the deck size is 24. Despite the size not being very big, the video claims that the game is tough to play. One more deck represents two permutations of 3 elements, and one must get to the identity on both of them. Thus, the deck size is 36, and the underlying group is S32. These games are sometimes called Non-abelian sets. A third deck is a deck with three crossing lines with beads. The crossing lines correspond to permutations of three elements, and each string either has a bead or not. To get to the identity, you need an even number of beads on each line. Thus, the deck size is 48 and corresponds to the group that is called the wreath product of C2 and S3, where Cn is the cyclic group with n elements. The wreath product is used because a copy of C2, each of the beads, is associated with each of the three lines that the first group, S3, is acting on.
The screenshot from the video we mentioned corresponds to this group, showing four cards forming a set. The red dot at the bottom signals the parity of a permutation, and there has to be an even number of them, but you can ignore them. However, the meaningful dots are small blue dots on some lines, and there has to be an even number of them on each line.
In practice, one card in each deck will contain the group identity, so this card is typically removed from such games. Leaving it in would allow anyone to add it to any other set they found, getting a free point (if the score is the number of cards for each set). Thus, the actual deck size contains 1 fewer card than the corresponding group.
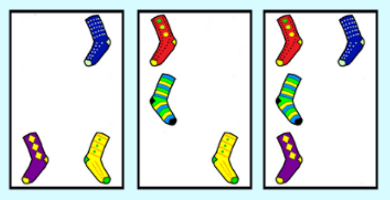
One famous example of such an extension of SET that wasn’t shown in the Numberfile video is often called “ProSet” (short for Projective Set). It is usually marketed under other names, for example, “Socks”. It is played on the group F26 with the identity card removed, making the deck 63 cards. The cards each contain some non-empty subset of 6 colored dots/socks. A set is any group of cards where each color appears an even number of times. This is equivalent to adding vectors in F26 and having them add to the identity: the zero vector. Since the group operation is addition, which is commutative, the sets found do not need to be in a particular order. The picture shows a set in the game of Socks.
However, there is a fundamental difference between the classic game of SET and the extensions we have talked about. No card in the SET deck obviously corresponded to the identity and had to be removed. It is almost as if the SET group “forgot” about its identity element. A group that has “forgotten” about its identity can be informally called a torsor. A torsor has a more sophisticated definition, but this casual one will do for our purposes. We also note that SET sets always contain exactly three cards. The sets have the following property: if we had chosen a particular assignment of the values of 0, 1, and 2 to each property, as in the Numberphile video, we would find that changing this assignment would have the following effect: if the initial set has all attributes different, the set will not change; if the attributes are all the same, each value would be shifted by the same shift s. The sum would thus be shifted by 3s = 0, as we look at everything mod 3.
Another affine game is a game of EvenQuads played on a deck of size 64. Each card has 3 attributes with 4 values each. Each card has symbols of a color (red, yellow, green, or blue), a shape (spiral, polyhedron, circle, square), and a quantity (from 1 to 4). The set, called quad in this game, consists of four cards such that for each feature, one of three things is true: 1) all of the cards are the same, 2) all of the cards are different, and 3) the card’s values are divided fifty-fifty. The picture shows the set in this game.
Can we extend the notion of a torsor to ProSet? The answer is yes! EvenQuads is almost equivalent to the game of ProSet: you just need to pick the card corresponding to the origin and only allow sets with four cards. The four values of each attribute in EvenQuads represent all possible values of 2 different socks in ProSet/Socks. With 3 attributes, we can express all possible values of 6 dots/socks. This is more restrictive than the set that we could choose in ProSet, but the advantage is that our deck is now completely free of a choice of a particular identity value. ProSet can be used to play EvenQuads and vice versa (with the exception of the identity card); the “torsor-ness” of EvenQuads makes the definition of a set cleaner. Indeed, a set in EvenQuads is not any set of cards that forms a set in ProSet. See more about how different famous card games are equivalent to each other in the paper Card Games Unveiled: Exploring the Underlying Linear Algebra.
At this point, it is worth noting that nothing about the games of SET, ProSet, or EvenQuads requires the exact dimension chosen. The game of SET uses C3 as an underlying group and chooses to use 4 copies of it. Both ProSet and EvenQuads use 6 copies of C2. The choice of dimension, the number of copies, is usually made with practical considerations in mind to make the number of cards in the deck, 81 and 64, respectively, to be of a reasonable quantity. However, to design a new game, we only have to verify that the underlying group is satisfactory, and only then do we need to fix a dimension.
So, how would we generalize further? If each attribute was an element of Z4 instead of Z22, would that work? Recall that in the game of SET, we require three cards to sum to zero in Z32. In ProSet and EvenQuads, we also require the cards to sum to zero in Z26, where in ProSet, we use any number of cards, and in EvenQuads, we use four cards. Coming back to Z4, suppose we announce that x cards form a set if their sum is zero. If we want the cards that are all the same in each feature to form a set, we need x to be divisible by 4. If we choose x to be 4, we will lose the ability to select “all different” as a valid combination of attributes since 0+1+2+3 = 2 mod 4. Any other x that is divisible by 4 is too big to play. And in any case, we lose symmetry between different values. For example, when the attributes are divided fifty-fifty, sometimes they sum to zero, as in 1+1+3+3, and sometimes not, as in 1+1+2+2.
Is this it? Should we stop there? Let’s not. Let’s check Z5. To allow all cards to be the same, we will claim that sets must have 5 cards. The good news is that 0+1+2+3+4 = 0 mod 5. Suppose we define the set as 5 cards that sum to zero modulo 5. The big question is, can we define the rule without assigning the exact values to each attribute? Let’s look at an example of a set: 0,0,0,2,3. We can’t claim a set to be three of the same values, and two others are different. However, if we specify a relative order of our elements and allow 0,0,0,2,3 to be a set, then together with it, all shifted sequences correspond to a set; for example, shifting by 1 produces 1,1,1,3,4.
In particular, to make a game based on Z5, we can demand that our sets consist of 5 cards that add to the identity. The fact that each set has 5 cards means that we can use a torsor and do not need to explicitly specify the identity. If we represent our 5 attributes as points on a pentagon or lines pointing in one of 5 directions, we observe a remarkable pattern: the 5 values add to 0 exactly when there is a line of symmetry in the chosen attributes! Below, we see all possible ways to add 5 values mod 5 and arrive at 0, up to rotations. As an example, if we chose 3+2+1+2+2=0 mod 5, we would see that this corresponds to the second symmetry in the picture, which we can view as drawing an axis of symmetry “through the 2”.
This is a property unique to the number 5, and also for numbers smaller than 4. This is not true for larger sizes of groups; for example, 0+0+0+1+2+3=6 has no symmetries in Z6. Number 4 represents an interesting case. If we represent our 4 attributes as points on a square or lines pointing in one of 4 directions, we observe that when the 4 values add to 0, there is a line of symmetry in the chosen attributes. However, in the case of values 0, 0, 3, 3, or, 0, 1, 2, 3, there is a line of symmetry, but the values do not sum to zero.
So we have shown that a torsor of C5, the cyclic group of 5 elements, might make for a convenient group on which to play a variant of SET. A reasonable choice of dimension might be 3, making a deck of size 125. This game would then be played on a C53-torsor. This inspired the name of this game as, this has been shortened to C53T, pronounced “C-Set”. To illustrate a card, we use pentagons with an indicated vertex to denote an element of C5. We need 3 pentagons, one for each dimension. To help players work around the fact that cards often get turned around, each direction on each pentagon is assigned a color to help players tell them apart better. Additionally, the three pentagons are shaded to clarify which pentagon corresponds to each dimension. In the image below, we see a C53T set, where the symmetric axes in each of the three dimensions go through the red, orange, and “any” axes from top to bottom.
This and many other games can be found on tsetse website. The website has a description, and also allows for a solitaire play.
Finding sets in C53T is extremely hard, so this is not a game for casual players, but it does serve to illustrate what really makes a set a set. In everything discussed in this blog post, we either used a group with a clear identity (such as in the Numberphile video) or a commutative operation (such as in C53T). Is there any way to have a non-abelian group torsor to play a variant of SET? The answer is yes, but that is a story for another day.
A foam is a finite 2-dimensional CW-complex with extra properties. This one opening sentence is already more advanced than any of my usual blog posts. Let me define a finite 2-dimensional CW-complex in layman’s terms.
To construct such a CW-complex, we can start with a bunch of discrete points. This will be the 0-dimensional part of our future CW-complex. To continue, we glue-in segments between some pairs of points, making the whole thing into a 1-dimensional CW-complex. We can view such a complex as a graph. Now, what we have left to do is glue some disks in. There are two ways to do it. First, we can take the disk’s border and attach it to one of the points. Second, we can glue the border of the disc to a cycle in a graph.
The previous paragraph explained how to construct a finite 2-dimensional CW-complex. Foams have additional properties. Given a point in the CW-complex, its neighborhood needs to be homeomorphic to one of three objects:
An open disc. Such points are called regular points. These are any points from inside of the discs.
The product of a tripod and an open interval. Such points are called seam points. These are any points from inside of the segments. To meet the tripod condition, all the segments have to attach themselves to three discs.
The cone over the 1-skeleton of a tetrahedron. Such points are called singular vertices. This means our starting vertices can’t remain unattached. The underlying 1-skeleton of our complex has to be a 4-regular graph (each vertex has to have degree 4). Moreover, any two edges coming from the same vertex must be on a disc’s border.
Some of the coolest foams are tricolorable. A foam is called tricolorable if it is possible to color its faces each in its own color by using three colors total so that at the seams, the faces of all three colors meet.
I first heard about foams during my brother Mikhail Khovanov’s lecture. He made a fascinating claim about tricolorable foams. If you remove regular points of a particular color from a foam, then the neighborhood of each point is an open disc. I was so curious, I decided to make a physical model. My readers know I hate crocheting, so I thought making a model out of felt would be easier. Thus, I made a tricolored neighborhood of a singular point. The two pictures show the same model from different angles.
Then, I needed to check my brother’s statement and made the same model with one color attached to the foam by zippers. This way, I can actually unzip one color and see the result. This color in real life is neon-green but looks yellowish in the pictures.
Guess what? The result was a smooth neighborhood isomorphic to an open disc. My brother was right!